SwiftSage: Building AI Agents for Complex Interactive Tasks via Fast and Slow Thinking with LLMs
Large language models (LLMs) like GPT-4 have revolutionized the field of AI by demonstrating exceptional performance in various reasoning tasks. However, the majority of this research has been limited to static environments, such as solving math problems or answering factoid questions. This raises the question: can LLMs be used for complex interactive tasks in the real, physical world? Imagine having an agent that could help complete everyday embodied tasks; can LLMs accomplish this?
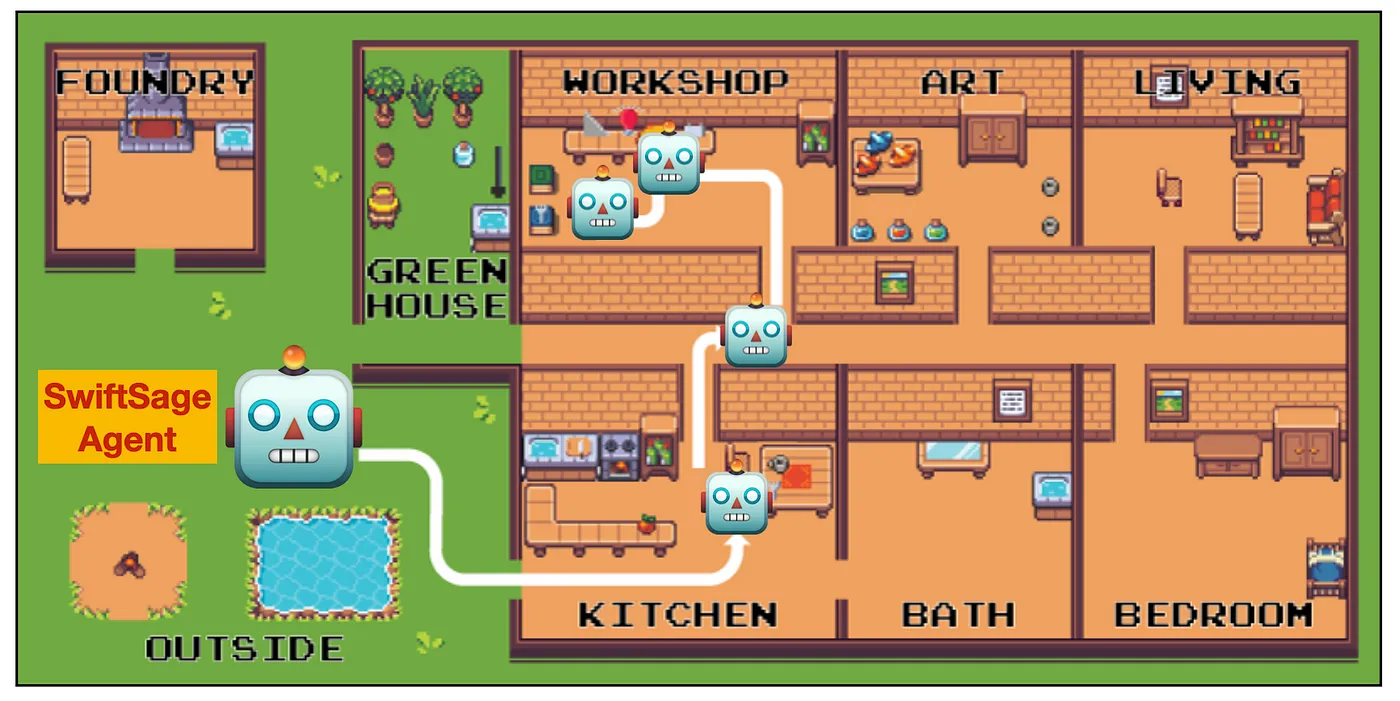
Take, for instance, the task of testing the electronic conductivity of an unknown object, which is in the ScienceWorld benchmark. An AI agent would have to navigate multiple rooms, locate items such as batteries and light bulbs, construct a circuit, conduct an experiment, and interpret the results. Successfully completing such complex interactive tasks is no small challenge — it demands that agents not only understand dynamic real-world scenarios but also possess higher-order cognitive and reasoning abilities. These may include long-horizon planning, task decomposition, efficient memorization, commonsense reasoning, and exception handling.
Previous methods
Researchers have primarily taken three different approaches for building agents: reinforcement learning (RL), behavior cloning (BC) from oracle agents, and prompting LLMs such as GPT-4. The latter shows much better performance but suffers from higher costs and error-proneness. Recent works like SayCan, ReAct, and Reflexion have made advancements in the field, but a crucial question still looms: Can we further maximizing the power of LLMs in planning and reasoning while minimizing costs?

Enter SwiftSage, an AI agent framework inspired by the dual process theory of human cognition featured in the renowned book Thinking, Fast and Slow. This theory proposes two distinct human thinking systems: System 1, characterized by rapid and intuitive thought; and System 2, which emphasizes analytical and deliberate reasoning. By integrating both thinking modules, we seek to optimize the agent’s potential for planning complex interactive tasks while minimizing the cost of its reasoning.
SwiftSage: Thinking, Fast and Slow

In our latest research paper from AI2 and USC, we introduce the groundbreaking SwiftSage framework, designed to develop AI agents that mimic human problem-solving abilities for complex tasks using fast and slow thinking processes. It is composed of two primary modules: the Swift module, simulating System 1, and the Sage module, emulating System 2. By effectively integrating these two modules, we can harness the power of both imitation learning and LLM prompting within the same agent framework.

The Swift module is an encoder-decoder based LM designed to quickly process short-term memory content such as previous actions, current observations, and the environment state. It simulates the fast, intuitive thinking characteristics found in System 1. By using the behavior cloning method and leveraging vast amounts of offline data generated by oracle agents, the Swift module is able to effectively understand the target environment and the requirements of the task at hand.
On the other hand, the Sage module represents the deliberate thinking process of System 2, harnessing the power of large language models (LLMs) like GPT-4. This module employs a two-stage process: planning and grounding. In the planning stage, LLMs identify needed items, develop and track subgoals, and handle any potential exceptions. The grounding stage then translates these planned subgoals into a sequence of executable actions using action templates. Notably, this approach differs from previous methods that generate actions sequentially at each time step.

A heuristic algorithm plays a crucial role in determining when to activate or deactivate the Sage module. For instance, when the Swift agent receives feedback indicating a failed action, this serves as a signal to switch to the more deliberate and detailed planning provided by the Sage module. Also, our algorithm effectively transforms the Sage’s outputs in valid actions in the target environment using an action buffer mechanism.
Evaluation
In a comprehensive evaluation using 30 tasks from the ScienceWorld benchmark, SwiftSage surpasses other methods, achieving a state-of-the-art average score of 84.7 (out of 100). In comparison, alternative approaches such as SayCan scored 33.8, ReAct obtained 36.4, and Reflexion reached only 45.3 (even after multiple trials). Additionally, SwiftSage proves to be significantly more cost-effective and efficient.

Thanks to its dual-system design for fast and slow thinking, SwiftSage dramatically reduces the number of tokens necessary for each action in LLM inference, making it more cost-effective and efficient than relying solely on the prompting-based method. On average, Saycan and ReAct require nearly 2,000 tokens to generate an action, Reflexion demands close to 3,000 tokens, while SwiftSage needs only about 750 tokens. Furthermore, SwiftSage showcases superior efficiency in interactive tasks, achieving the same scores with fewer actions, as illustrated in the graph below.
Conclusion
To advance AI, we must develop agents adept at complex interactive reasoning in real world. We introduce SwiftSage, an innovative framework inspired by the dual-process theory of human cognition that delivers state-of-the-art performance, increased efficiency, and reduced cost. We believe that such dual-process agents, which harness the strengths of both small and large LMs, are pivotal in addressing complex interactive reasoning tasks and building general AI agents. The advancements achieved with SwiftSage bring us a step closer to unlocking the full potential of LLMs in action planning, empowering us to tackle intricate real-world problems in a more cost-effective manner.
Links
- Paper: https://arxiv.org/abs/2305.17390
- Website: https://yuchenlin.xyz/swiftsage/
- Code: https://github.com/allenai/ScienceWorld/
References
- React: Synergizing reasoning and acting in language models. ArXiv, abs/2210.03629, 2022.
- Reflexion: an autonomous agent with dynamic memory and self-reflection. ArXiv, abs/2303.11366, 2023.
- Do as i can, not as i say: Grounding language in robotic affordances. In Conference on Robot Learning, 2022.
- Scienceworld: Is your agent smarter than a 5th grader? In Conference on Empirical Methods in Natural Language Processing, 2022.
Follow @allen_ai on Twitter and subscribe to the AI2 Newsletter to stay current on news and research coming out of AI2.
